過去兩週,我們從 OpenAI API 基礎起步,學會在 Node.js 中串接 GPT 模型,並運用 LangChain 框架打造更靈活的 AI 應用流程。然而,大型語言模型仍有一項先天限制:它的知識止步於訓練資料。當應用情境需要引用最新資訊、專案內部文件,或是特定領域的知識庫時,模型不僅可能答不上來,還可能出現「幻覺」,生成看似合理卻錯誤的內容。
從今天起,我們將踏入 RAG(Retrieval-Augmented Generation) 的主題,學習如何將外部檢索與模型生成相結合,突破大型語言模型的知識侷限,進一步打造更智慧、更可靠的 AI 應用。
RAG 全名 Retrieval-Augmented Generation,中文常譯為「檢索增強生成」,是一種將大型語言模型(LLM)與外部知識來源結合的技術架構。它的核心目標,是解決 LLM 僅依賴訓練資料回答問題所帶來的限制,例如知識過時、內容不完整,甚至可能產生「幻覺」(Hallucination)等問題。
在 RAG 的典型流程中,系統在接收到使用者查詢後,會先透過檢索模組,從知識庫(如文件、資料庫、網頁或 API)中搜尋最相關的內容;接著,將這些檢索結果與使用者的問題一併輸入 LLM 的提示詞(Prompt)中,作為生成回應的上下文依據。如此一來,模型的回答不再僅僅依靠自身的訓練資料,而是能結合外部知識來源,提供更精確、即時且有依據的回應。

事實上,在前面的實作中,我們已經打造過一個「具備網路搜尋能力的 AI 部落格寫手」。它在撰寫文章前,會先從網路檢索最新的相關資料,再交由模型生成內容。這其實就是一種 RAG 的應用,只不過當時的檢索來源限定於即時網路搜尋。接下來,我們將更進一步,探討如何讓 RAG 連接到各種自訂知識庫,以支援更多元的使用場景與需求。
RAG 可以想成是一種「先找資料,再讓 AI 寫答案」的流程。它將 LLM 的自然語言生成能力,與外部知識檢索系統結合,讓回應不再只依賴模型訓練時的知識,而是能根據最新、特定領域或私有的資料來生成結果。
RAG 的運作主要分成兩大步驟:檢索(Retrieval) 與 生成(Generation)。
檢索階段的目標,是從龐大的資料庫中找出與使用者問題最相關的內容,並提供給模型作為生成依據。這些資料來源可能包括:
為了有效比對問題與資料的語意相關性,RAG 系統通常會使用 向量搜尋(Vector Search) 技術。這個過程大致可分為以下步驟:
檢索的品質將直接影響最終生成結果的正確性。換言之,如果檢索到的內容偏離問題核心,即便是再強大的大型語言模型也可能產生錯誤或模糊的回應。
生成階段的任務,是將前一步檢索到的相關內容與使用者的原始問題結合,讓 LLM 在具備上下文資訊的情況下生成更準確的回應。
這一步的核心關鍵在於 Prompt 設計,常見的做法包括:
範例如下:
你是一個專門負責問答任務的助理。請根據以下檢索到的內容回答問題。
如果你不知道答案,請直接回答「我不知道」。
回答請限制在三句以內,並保持簡潔。
問題:{question}
內容:{context}
回答:
透過這樣的設定,LLM 會被約束在指定的資料範圍內作答,降低產生「幻覺」的風險,同時也能更聚焦於引用最相關的資訊,提供穩定且有根據的回答。
要打造一個完整的 RAG 系統,通常需要幾個核心元件。這些元件各自負責不同的功能,彼此協同運作,才能讓系統從「輸入問題」到「生成答案」的流程順暢完成。
嵌入模型的主要任務,是將自然語言的文字轉換為數值化的向量表示,讓電腦能夠計算語意相似度。這些高維度的數字陣列能捕捉語句的語意特徵,而不只是單純進行字面比對。當使用者的提問與知識庫中的文件都被轉換為向量後,系統就能利用數學方法(例如餘弦相似度)來判斷它們之間的相關程度。
在實務應用中,OpenAI 提供的 text-embedding-3-small 與 text-embedding-3-large 是常見的選擇。text-embedding-3-small 成本較低且運行速度快,適合即時檢索或對精度要求不高的場景;而 text-embedding-3-large 在語意表達上更為精準,特別適合多語言檢索、技術文件比對,或需要高度準確性的應用情境。
向量資料庫專門用來儲存與檢索向量化的資料。與傳統的關聯式資料庫不同,它針對「相似度查詢」進行優化,能夠快速找出與查詢向量距離最近的資料片段。除了存放向量本身之外,這類資料庫通常也會保留原始內容及其相關的 metadata(例如來源檔名、段落位置),方便後續生成答案時引用。
目前常見的向量資料庫包括 Chroma、Qdrant、Pinecone、Weaviate、Faiss 等。在選擇時,需同時考量系統的可擴展性、查詢延遲、支援的相似度演算法、與既有系統整合的便利性,以及是否需要雲端服務或自建部署的彈性,才能確保能夠符合實際應用場景的需求。
檢索器的任務是接收使用者的問題,將其轉換成向量,並在向量資料庫中找出最相關的內容片段,作為生成模型的依據。它是串聯「使用者輸入」與「資料庫內容」的關鍵橋樑。
在實務上,最常見的方式是使用 Top-K 檢索來篩選出相似度最高的片段,並透過閾值過濾無關內容,避免影響生成的正確性。若應用場景對準確性要求更高,則可採用混合檢索,讓系統同時考量語意相似度與關鍵字匹配,以獲得更可靠的查詢結果。
生成模型是 RAG 系統的最後一環,負責將檢索到的上下文與使用者的原始問題結合,產生流暢且準確的自然語言回應。即便檢索階段提供了正確的內容,最終答案的品質仍高度依賴生成模型的表達能力、推理能力,以及對指令的遵循程度。
在 RAG 中,生成模型並非自由發揮,而是必須被限制在檢索內容的範圍內進行回答。這就需要透過精心設計的 Prompt,明確指示模型只能根據檢索資料作答,從而降低幻覺發生的風險,並確保回應始終建立在可靠的知識基礎上。
在 LangChain 中,RAG 的實作並不是透過單一模組完成,而是由多個元件協同運作,將資料處理、檢索與生成串接成一個完整流程。這種模組化設計讓開發者能夠靈活替換不同環節的實作,例如改用不同的向量資料庫、嵌入模型或檢索策略,以因應各種應用需求。
主要涉及的核心模組包括:
DocumentLoader:負責載入各種格式的資料,將它們轉換成 LangChain 可處理的 Document 物件。TextSplitter:將長篇文件切分為較小的片段(Chunk),方便後續向量化並提升檢索的精準度。Embeddings:將文字片段轉換成數值向量,作為語意搜尋的基礎。VectorStore:負責儲存與管理向量資料,並提供檢索功能。Retriever:接收使用者查詢並從向量資料庫中擷取最相關的內容片段,作為 LLM 生成答案的依據。以下是簡化的 RAG 架構流程示意圖:
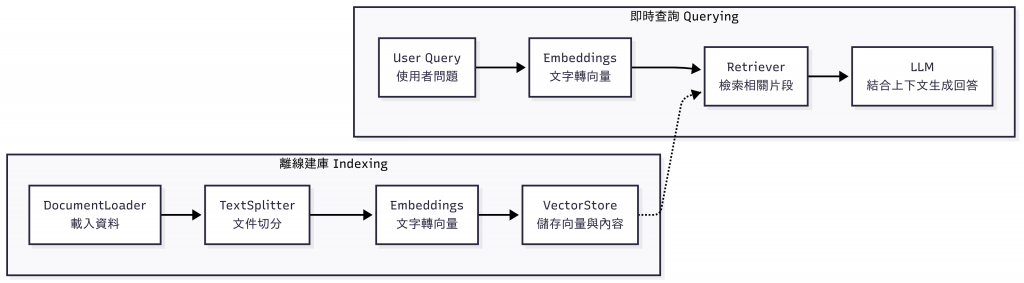
整體流程可以分為兩個階段:
在接下來的內容中,我們會逐步拆解這些模組,並透過程式碼實作,帶你完整掌握如何在 LangChain 中建構一個 RAG 系統。
今天我們正式進入 RAG(檢索增強生成) 的主題,理解它如何結合外部知識庫與 LLM,解決知識過時與幻覺問題:
DocumentLoader → TextSplitter → Embeddings → VectorStore → Retriever → LLM。RAG 讓 AI 不再侷限於模型內建知識,而能靈活結合最新、專屬或私有的資料庫,成為更可靠的智慧助理。接下來,我們會逐步拆解並實作這些元件,帶你真正動手打造一個 RAG 系統。
本系列文已正式出版為《Node.js 生成式 AI 應用開發實戰:實作 OpenAI API × LangChain × LangGraph × RAG,打造從雲端到本地 LLM 的混合式安全架構》。內容全面升級,提供更完整的實戰範例與 LLM 應用架構設計。歡迎參考選購,開啟你的生成式 AI 開發之路!
天瓏網路書店連結:https://www.tenlong.com.tw/products/9786264144964


